项目案例2——大规模样本送检分配简易数学模型
2020年,新冠病毒突然爆发。某地发生不明原因的大规模病毒感染,病毒传播力极强,严重威胁人民群众的生命健康。快速检测出病毒感染者并采取医学措施,是尽快遏制病毒传播的有效手段。
面对突如其来的巨大检测样本量,由于统筹调度力度不够和基础信息掌握不全,导致样本送检分配不均。
二、发现的问题
1. 部分检测单位爆仓
样本量远超检测能力,无法在规定时间完成检测,导致检测滞后
2. 部分单位"吃不饱"
样本量少于检测能力,造成人力物力浪费,资源利用率低
3. 时间延误风险
检测结果出具延迟,影响疫情防控决策和患者治疗
4. 统筹调度困难
基础信息掌握不全,导致样本送检分配不均
三、真实数据分析
通过对某市5家检测机构的调研,我们获得了以下真实数据:
| 合计 | 22,000 份 | 25,000 份 | 75.2% |
问题核心:总检测能力22,000份,却只能完成75.2%
四、资料收集
检索中国学术期刊网、万方数据资源系统、维普科技期刊文摘索引等资源,均未查到与本课题有关或沾边的文献。
本课题具有一定的创新性和实用价值,为大规模样本分配提供了新的解决思路。
五、数学模型设计
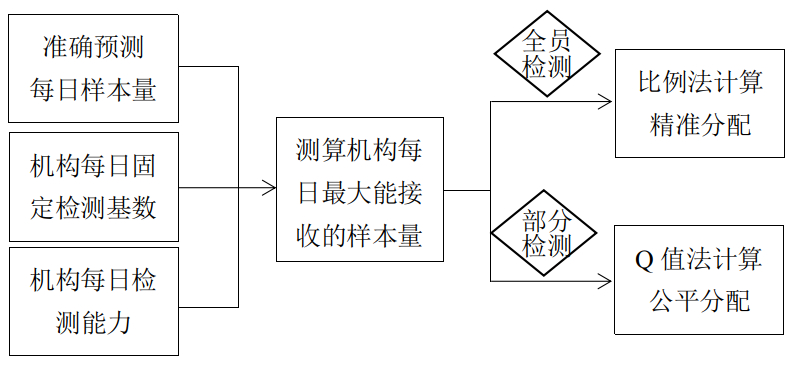
数学符号约定
核心公式
xi = (mi / N) × 待分配样本
各机构分配的样本量 = (该机构可接收量 / 总接收量) × 待分配总量
六、模型应用效果
优化前后对比
具体分配方案对比
七、研究过程
本次研究从理论角度对大规模样本送检分配进行研究。通过发现问题、研究方案、数学运算、解决问题的实践,对相关单位针对有可能出现的病毒致病力增强变异株的应对,有较大的现实意义和实用价值。
通过数学模型解决实际问题的初探和效果,也让我感受到:平常我们课堂上所学的数学知识,原来也可以切实解决日常生活的实际问题。
八、创新点与价值
核心创新
• 首次研究:从理论角度对大规模样本送检分配进行系统研究 • 实用价值:对疫情防控有较大的现实意义和实用价值 • 学以致用:让初中生感受到数学知识可以解决实际问题
应用场景
• 核酸检测分配 • 血液样本分配 • 药品配送分配 • 物流仓储分配
作者:笑蓉科技
🦀 四川笑蓉科技
本文由笑蓉科技供稿 由🦀笑蓉科技小助理🦀笑哈哈小螃蟹编辑发布